CHRIS MCCORMICK
AI Researcher in Transformer Efficiency & Interpretability
I design and analyze Transformer architectures with shared subspaces in their Attention and MoE layers, incorporating insights from interpretability.
Currently open to Research & Engineering roles.

Recent Work
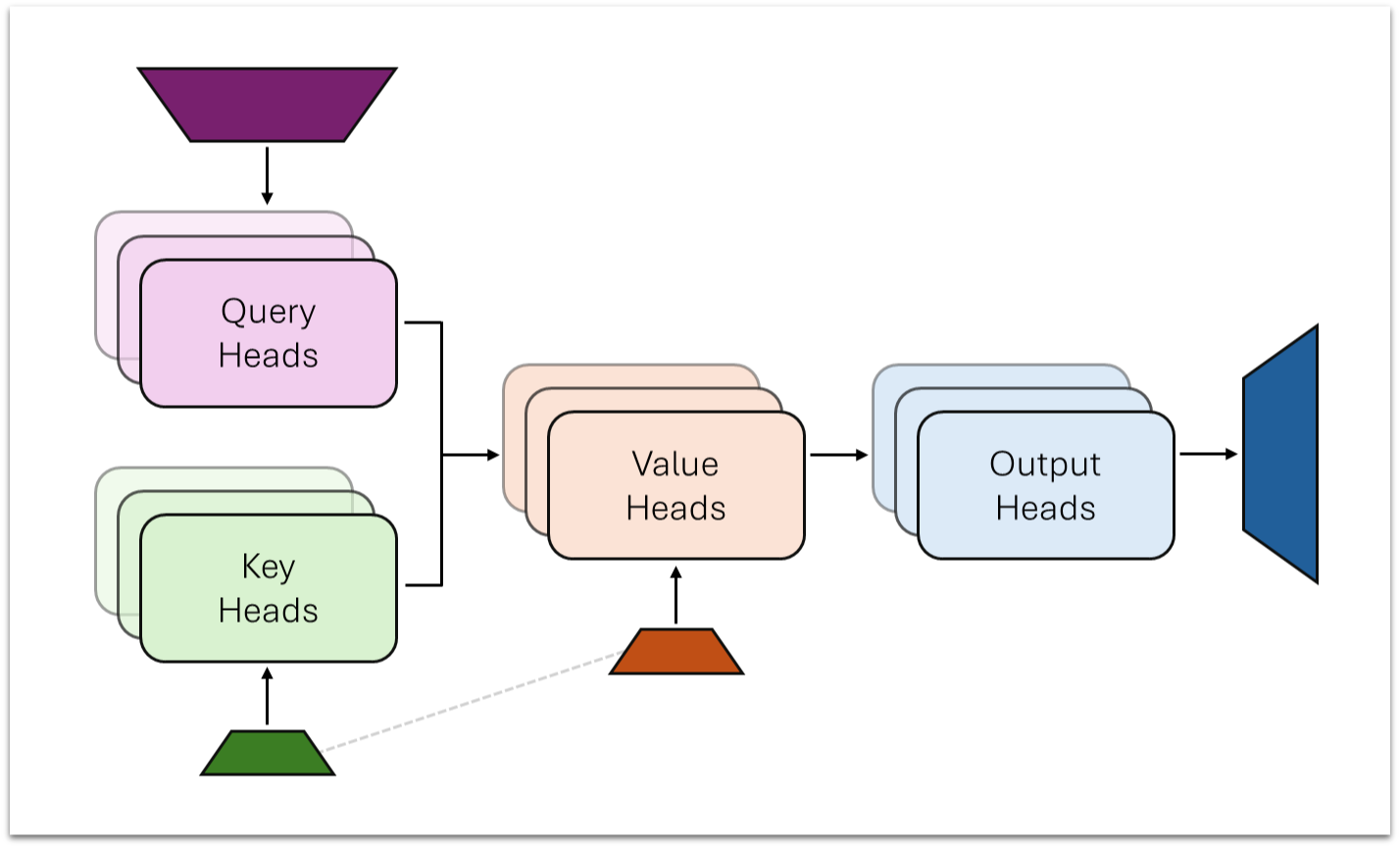
Output Subspaces for Multihead Latent Attention
(July 2025 - Present)
Multihead Latent Attention (MLA) defines shared latent spaces for queries, keys, and values. This project investigates the natural next step: a shared latent space for the attention output.
-
Performed Singular Value Decomposition (SVD) on the output matrices () of all attention layers in DeepSeek-V3 and Kimi-K2, revealing low effective rank, particularly in earlier layers.
-
Implemented shared output subspaces based on the SVD analysis to measure reconstruction error and potential parameter savings.
-
Currently conducting small-scale pre-training experiments with Vision Transformers and BERT-style encoders to assess the impact of this architectural change on downstream performance.
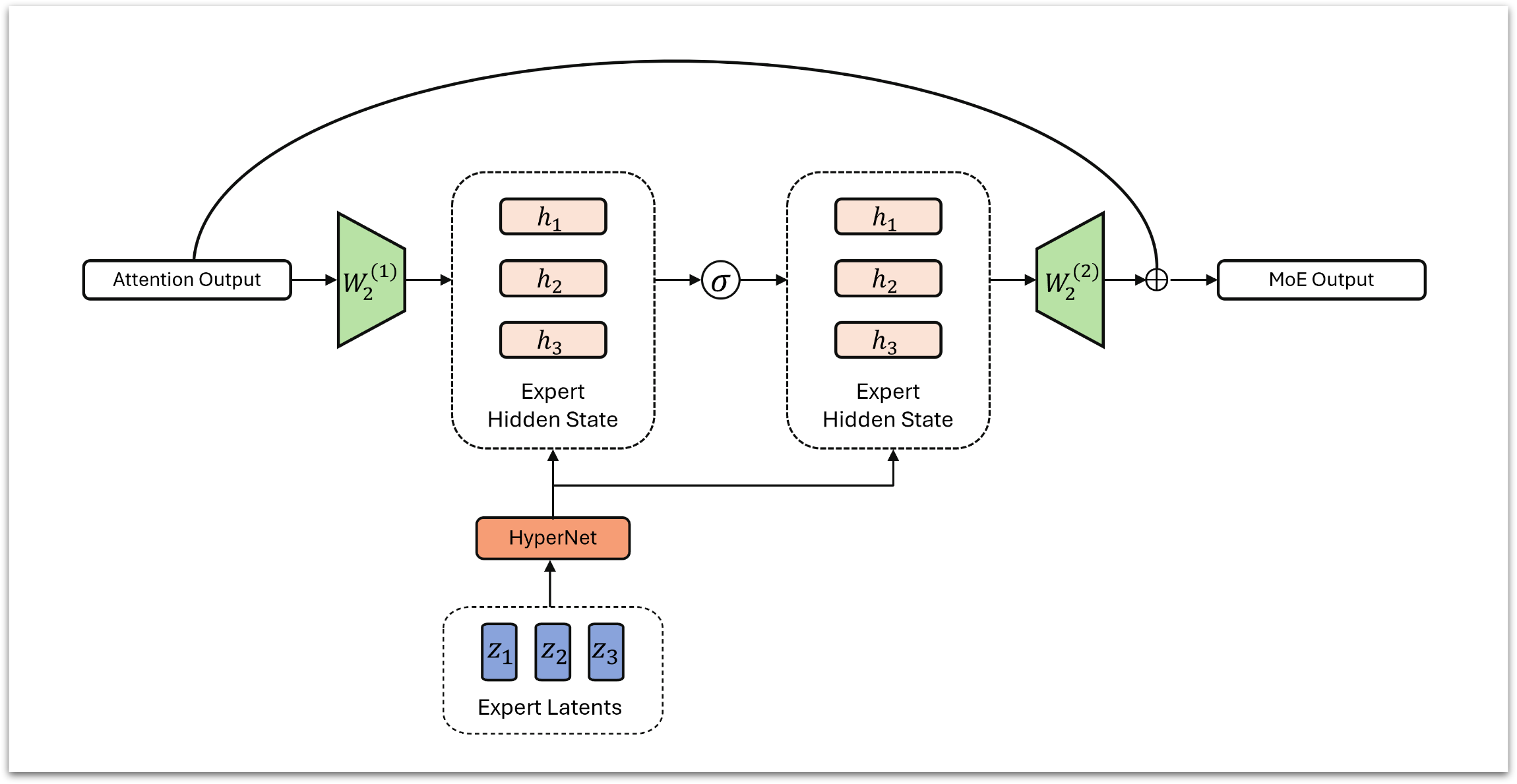
ETHOS: Efficient Transformer with Latent MoE
(Community Project, May 2025 - Present)
ETHOS is a novel architecture developed with a community research group that combines several latent space techniques into a single, efficient model. Its core components include MLA, shared expert subspaces (inspired by MoLAE), and single-neuron experts with Product-Key routing (PEER). The model uses a small generator network to create full-sized expert weights on-demand, rather than storing them.
My primary contribution was redesigning the expert generation and application logic. By re-ordering the matrix operations and implementing them in a custom Triton kernel, I achieved an 8x speedup in the training throughput for this part of the model. We are currently running ablations and experiments to assess downstream performance.
(Source code and preliminary write-up coming soon)
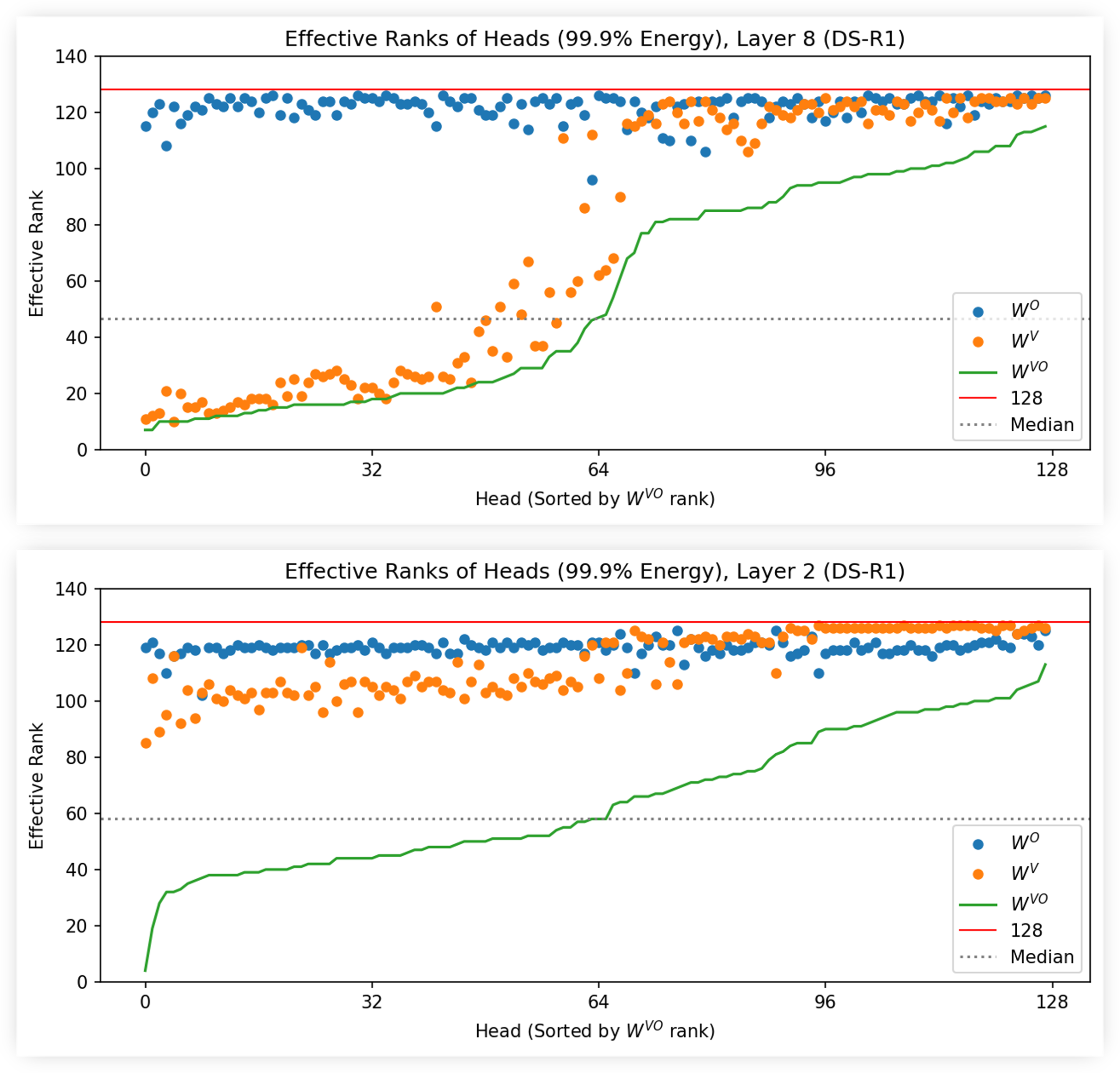
SVD Analysis of Attention Matrices in MLA Models
(June - July 2025)
Conducted a comprehensive SVD analysis of all attention weight matrices in the DeepSeek-V3 and Kimi-K2 models. This included the query, key, value, and output projections (), the shared latent subspaces for keys/values and queries, and the Rotary Position Embedding (RoPE) heads.
-
Key findings show a consistently low effective rank in the early layers of the models.
-
Analysis of fused matrices (WVO, WQK) revealed further reduction in effective rank.
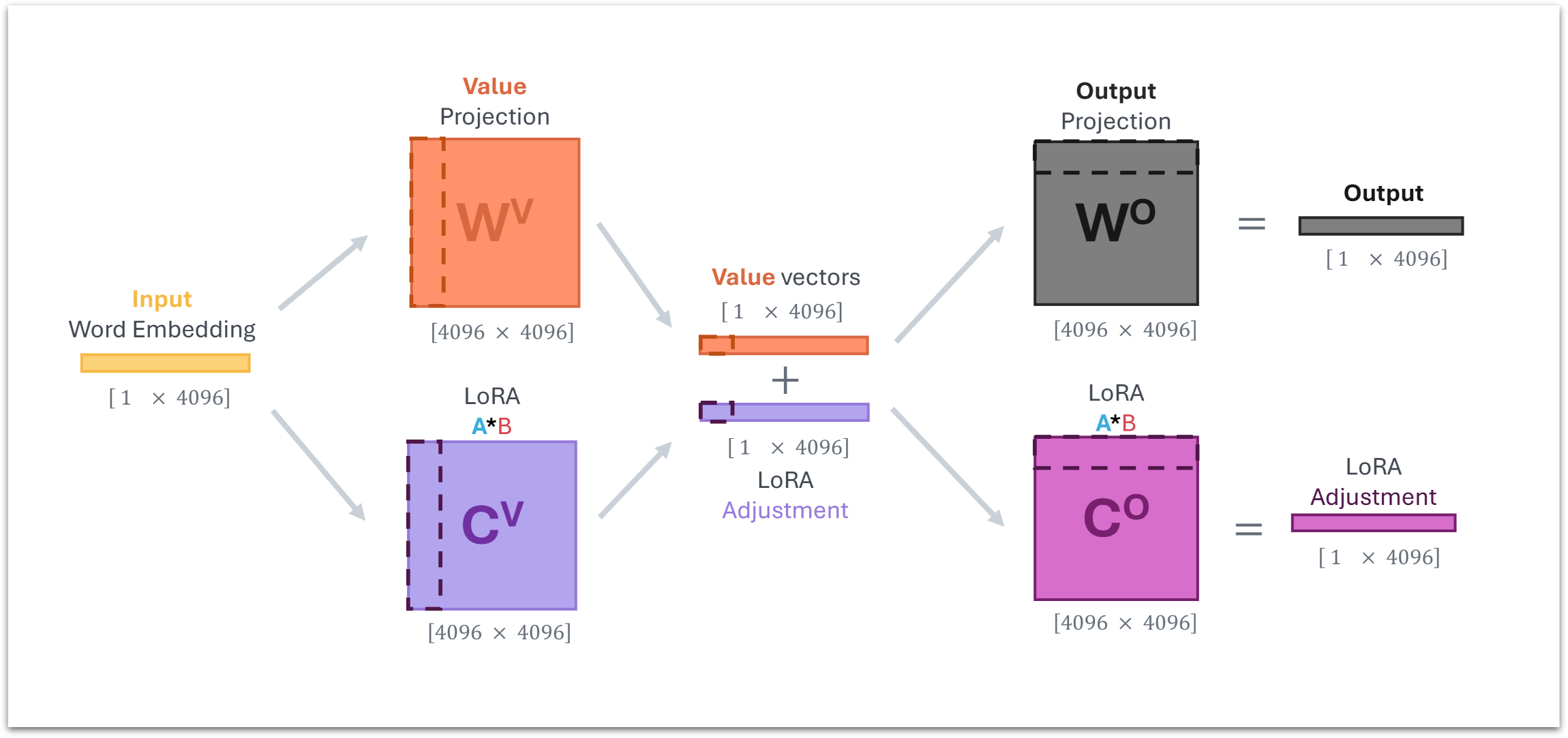
A Per-Head Interpretability Perspective on LoRA
(Spring 2025)
Low-Rank Adaptation (LoRA) is typically presented as a "black box" low-rank update (B ) to a model's weight matrices. This work moves beyond that view by combining the algebra of attention and LoRA to derive a more direct, mechanistic understanding of its effects on individual heads and the composition of heads. This framing provides a more intuitive grasp of how LoRA fine-tunes model behavior.
(Write-up and illustrative experiments planned)